
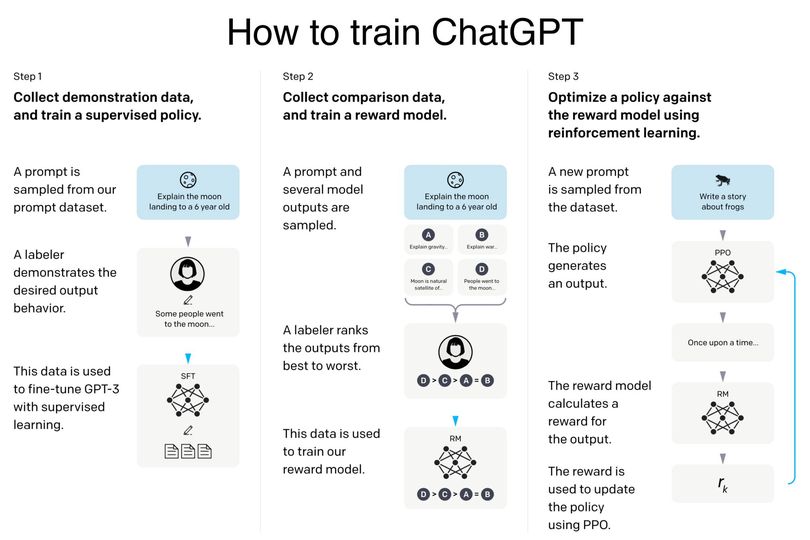

Hello Stackers,, Do you know how ChatGPT was trained? ChatGPT is “simply” a fined-tuned GPT-3 model with a surprisingly small amount of data! Moreover, InstructGPT (ChatGPT’s sibling model) seems to be using 1.3B parameters where GPT-3 uses 175B parameters! It is first fine-tuned with supervised learning and then further fine-tuned with reinforcement learning. They hired 40 human labelers to generate the training data. Let’s dig into it!
– First, they started by a pre-trained GPT-3 model trained on a broad distribution of Internet data (https://arxiv.org/pdf/2005.14165.pdf). Then sampled typical human prompts used for GPT collected from the OpenAI website and asked labelers and customers to write down the correct output. They fine-tuned the model with 12,725 labeled data.
– Then, they sampled human prompts and generated multiple outputs from the model. A labeler is then asked to rank those outputs. The resulting data is used to train a Reward model (https://arxiv.org/pdf/2009.01325.pdf) with 33,207 prompts and ~10 times more training samples using different combination of the ranked outputs.
– We then sample more human prompts and they are used to fine-tuned the supervised fine-tuned model with Proximal Policy Optimization algorithm (PPO) (https://arxiv.org/pdf/1707.06347.pdf). The prompt is fed to the PPO model, the Reward model generates a reward value, and the PPO model is iteratively fine-tuned using the rewards and the prompts using 31,144 prompts data.
This process is fully described in here: https://arxiv.org/pdf/2203.02155.pdf. The paper actually details a model called InstructGPT which is described by OpenAI as a “sibling model”, so the numbers shown above are likely to be somewhat different.